6.2 Monitor server installations
6.2.1 Monitor workloads using Performance Monitor, Server Manager, Event Viewer
6.2.2 Configure Data Collector Sets
6.2.5 Monitor workloads using Resource Monitor
6.2.1 Monitor workloads using Performance Monitor, Server Manager, Event Viewer
Performance Monitor er et verktøy soom viser statistikk for ytelsen til systemet, i sanntid. Hver statistikk kalles Performance Counter, og det er hundrevis av dem. Man kan opprette tilpassede grafer med informasjonen man ønsker.
Åpne programmet Performance Monitor. Den første siden man får opp er en oversikt over status for systemet. Trykker man på Monitoring Tools > Performance Monitor får man opp en graf om prosessorutnyttelsen i sanntid. Nederst ser man informasjon om hver performance counter som måles i grafen, og man kan skru av/på en counter.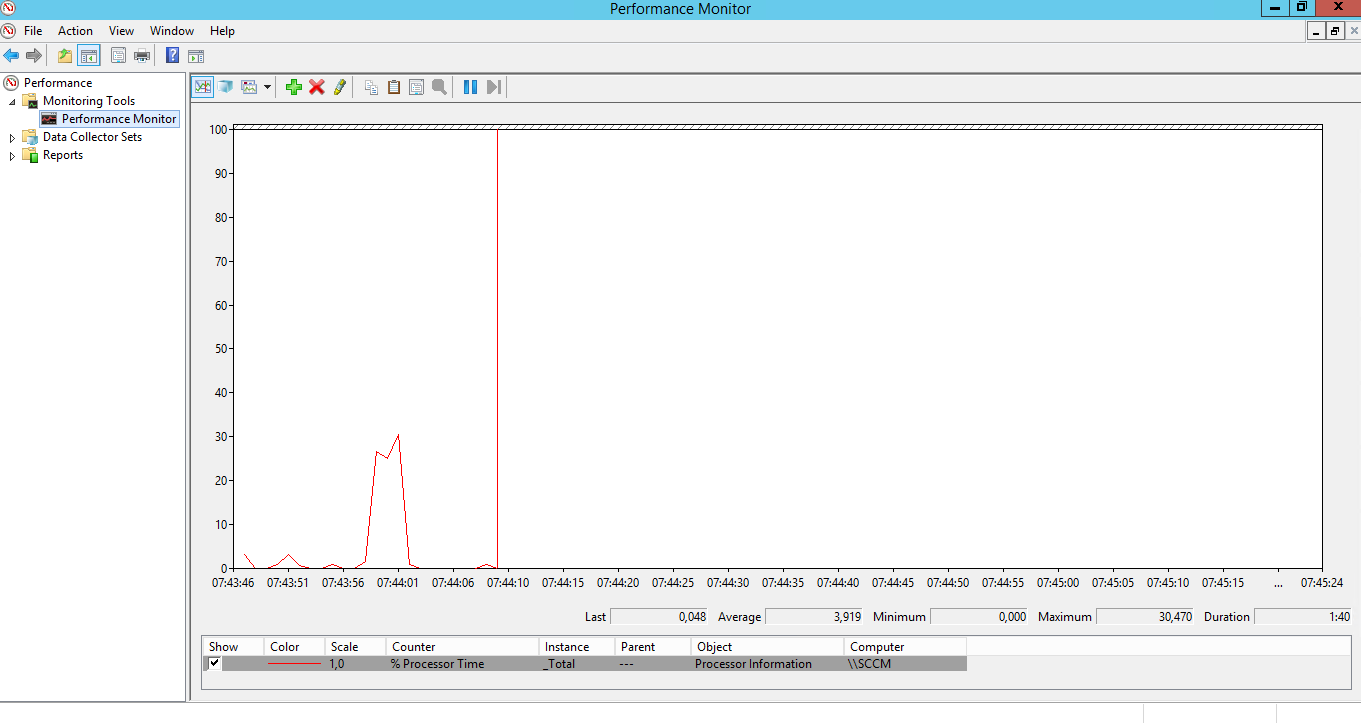 Linjen i den første, standard grafen kan være vanskelig å se. Man kan gjøre det enklere å se ved å modisifere Y-aksen.
Linjen i den første, standard grafen kan være vanskelig å se. Man kan gjøre det enklere å se ved å modisifere Y-aksen.
CTRL + Q > Graph > reduser Maximum verdien.
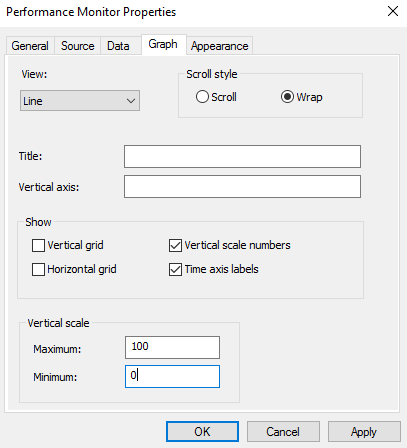
Dette bør justeres for hver counter for å gi en best mulig graf. Mer at ikke alle countere baserer seg på prosentandel belastning. Utfordringen er å flere ulike countere til å fungere godt sammen i samme graf. Merk at man kan endre flere andre ting om hvordan grafen ser ut i Performance Monitor Properties (CTRL + Q).
Andre grafer
I tillegg til den grafen vi har sett har man to andre visninger av samme data; histogram og rapport. Disse viser kun nåværende status, ikke historisk status.
Man velger visninger ved å trykke CTRL + G.
Histogram: Rapport:
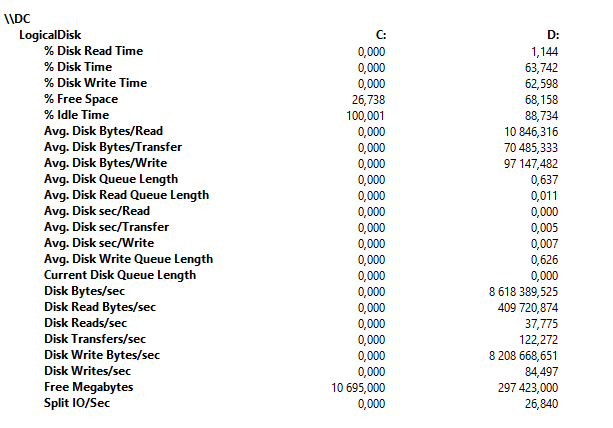
Rapport:
Legge til en Performance COunter
For å legge til en Counter trykk CTRL + I:
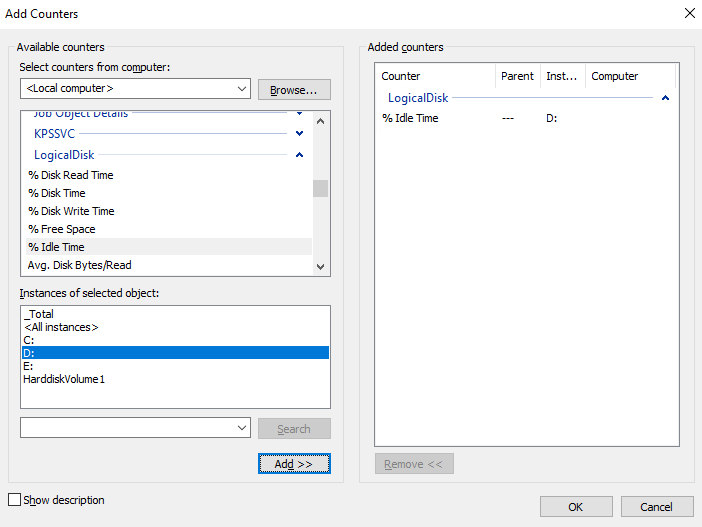
Her man man velge lokal maskin, eller en annen maskin å hente data fra. Man kan velge mellom mange forskjellige kategorier og Performance Counters her. Velg en counter og trykk Add >>>..
- Computer: Velg hvor data skal hentes fra. I motsetning til andre MMC snap-ins kan man ikke koble hele Performance Monitor til en annen maskin, bare individuelle counters.
- Performance Object: Hardware eller software komponent, trykk på pilen for å utvide og se hvilke counters som finnes for komponenten.
- Performance Counter: En statistikk som representerer et spesifikt aspekt ved et performance object sine aktiviteter.
- Instance: Identifiserer er en spesifikk instans, dersom det er flere av samme komponent. F.eks. to disker, eller to nettverkskort.
NB. Merk at ved å huk av for Show description, vil man få en detaljert beskrivelse av objektet eller counter som er valgt.
Kontrollere visningen
For å lage gode visninger bør man følge disse tipsene:
- Limit the number of counters: For mange counters gjør grafen vanskelig å tolke. Man kan heller splitte opp i flere vinduer, og fordele counters på vinduene på en hensiktsmessig måte. Alternativt bruk histogram eller report for å gi en mer kompakt visning.
- Modify the counter display properties: Man kan endre verdier på farge, tykkelse, og stil for hver graf for å gjøre de enklere og se.
- Choose counters with comparable values: Velg counters med statistikker som er praktisk å legge inn i samme vindu. Pass på at ulike countere måler i forskjellige verdier og skalaer. Hvis en counter har relativt veldig høy verdi, vil det bli vanskelig å lese de andre copunterene.
6.2.2 Configure Data Collector Sets
Flaskehalser i ytelsen han utvikle seg på servere over en lang periode, og det kan bli vanskelig å detektere de ved å observere ytelsesnivåer på et spesifikt tidspunkt. Da kan det være nyttig å bruke verktøy som Performance Monitor til å lage en baseline for serveren. Baseline er et sett med statistikk tatt under normale operasjonsforhold på serveren. Man kan senere sammenlikne ytelsen mot baseline for å oppdage avvikende trender som kan påvirke ytelsen.
For å lage en baseline: Performance Monitor > Data Collector > User Defined (høyreklikk) > New > Data Collector Set
Oppgi et navn og velg Create manually (Advanced)
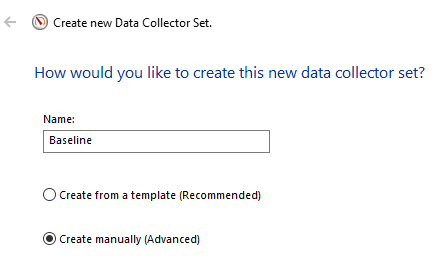
Velg hvilken type data som skal samles inn: Performance counter

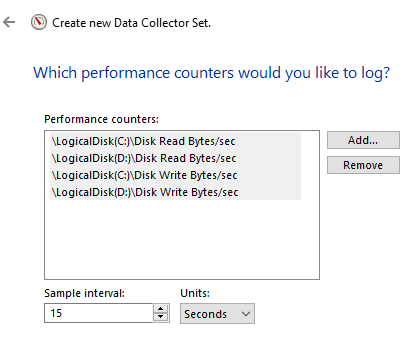
Velg counters som skal samles inn, og hvor ofte innsamlingen skal skje:
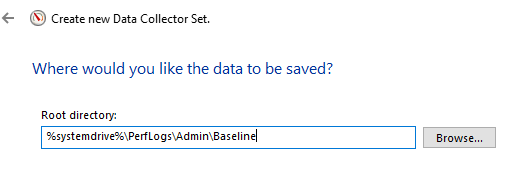
Velg hvor Data Collector Set skal lagres.
Velg hva som skal skje når innsamlingen er ferdig.
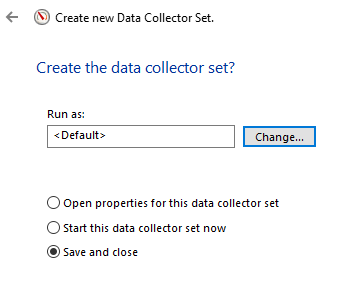
Når man har har opprettet baseline kan man dobbeltklikke på filen, som vil åpne den i Performance Monitor.
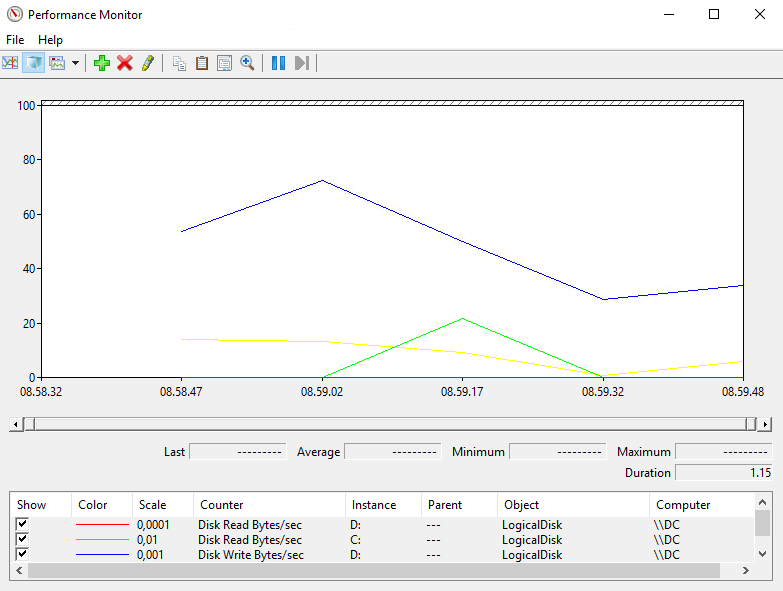
Ved å gjenta denne prosessen, åpne begge i Performance Monitor, kan man sammenlikne de.
6.2.3 Determine appropriate CPU, memory, disk, and networking counters for storage and compute workloads
Ofte når man må feilsøke, er det ikke åpenbart hva som er årsaken. Brukere kan si at maskinen er treg, og da er det ofte en Bottleneck (flaskehals) et sted. En bottleneck er en komponent som ikke gir akseptabel ytelse sammenliknet med andre komponenter i systemet. Har man f.eks. oppgradert til et raskere nettverket, kan det være at prosessor ikke klarer å holde tritt med antall operasjoner. Bottlenecks kan oppstå av mange forskjellige grunner. Noen av de inkluderer:
- Increased server load: En server kan fungere fint i utgangspunktet, men så skjer det noe unormalt med bruksmønsteret som påfører serveren ekstra arbeid. F.eks. en nyhet gjør at trafikken til en nettside tidobles.
- Hardware failure: Feil på hardware kan føre til nedsatt ytelse.
- Changed server roles: Forskjellige roller har forskjellige krav til serveren den skal kjøre på. En webtjener har andre krav enn en databaseserver. Database krever mer av prosessoren enn webtjeneren.
For å finne en bottleneck har man alt man trenger i Performance Monitor, men det betyr ikke at det er lett å finne. Som regel når det oppstår en bottlneck er det en av fire komponenter som er ansvarlig:
CPU counters
- Processor: % Processor TIme: Prosentandel av tiden hvor prosessor er opptatt. Bør være så lavt som mulig, helst under 85%. Hvis verdien konsistent er for høy, bør man undersøke hvilke prosesser som bruker mye av prosessoren, og enten løse problemet med prosessen eller oppgrader/kjøp en til prosessor.
- System: Processir Queue Length: Antall programtråder som venter på å få kjøre på prosessoren. Bør være så lavt som mulig, helst under 10. Hvis verdien er for høy, oppgrader eller legg til en til prosessor.
- Server Work Queues: Queue Length: Antall forespørsler som venter på å få bruke prosessoren. Bør være så lavt som mulig, helst under 4. Hvis verdien er for høy, oppgrader eller legg til en til prosessor.
- Processor: Interrupts/Sec: Antall hardware interrupts prosessoren behandler per sekund. Dette kan variere veldig , og er kun nyttig når man sammenlikner med en baseline. En hardware komponent som genererer for mange interrupts kan ta monopol på prosessoren, slik at prosessoren ikke får utført andre oppgaver.
Memory counters
For lite minne kan forhindre serveren fra å cache mye brukt data i stor nok grad. Er det ikke nok minne må man bruke disk, som er vesentlig tregere å lese/skrive. Minne er den viktigste komponenten å overvåke, da den kan påvirke alle andre systemer på serveren. Og da ser det ut som det er de systemene som har et problem, mens det egentlig er minnet som er årsaken.
En av de vanligste årsakene til minneproblemer er memory leak. Det er når en applikasjon har allokert inne til bruk, men ikke frigir minnet når den er ferdig/avsluttes. Over tid kan minnet bli helt fult på denne måten.
De fleste minneproblemer skyldes som regel tredjeparts applikasjoner, men det har hendt at også OS er synderen.
- Memory: Page Faults/Sec: Antall ganger i sekundet kode eller data, som skal prosesseres, ikke ligger i minnet. Verdien bør være lavest mulig, helst under 5. Inkluderer både soft faults (data finnes en annen plass i minnet), og hard faults (data må hentes fra disken). Soft faults går som regel greit, men hard faults går i stor grad ut over ytelsen. Har man for mange had faults bør man undersøke hvilken prosess som er synderen, eller man kan installere mer minne.
- Memory: Pages/Sec: Antall ganger i sekundet informasjon ikke var i RAM, og måtte aksesseres fra disk eller skrives til disk for å frigi minne. Verdien bør være lavest mulig, helst under 20. Er verdien for høy bør man undersøke hvilken prosess som er synderen, eller man kan installere mer minne.
- Memory: Available MBytes: Spesifiserer hvor mye ledig, fysisk minne har man i megabytes. Verdien bør være så høy som mulig, og bør ikke utgjøre mindre en 5% av totalt fysisk minne. For lav verdi kan bety at man har memory leak. Man kan installere mer minne, eller undersøke hva som skaper memory leak.
- Memory: Committed Bytes: Mengde virtuelt minne som har reservert plass på disken (disk paging files). Verdien bør være så lav som mulig, og alltid mindre en mengde fysisk RAM i systemet. Er verdien for høy, kan man installere mer minne, eller undersøke hva som skaper memory leak.
- Memory: Pool Non-Paged Bytes: Størrelsen på et område i minne, som OS bruker for objekter som ikke kan skrives til disk. Verdien bør være stabil, og bør kun gå opp ved økt aktivitet på server. Hvis verdien øker over tid kan det indikere memory leak.
Disk counters
For mye aktivitet på disken kan gjøre at køen med klientforespørsler bare øker og øker. Dette kan fort skje hvis man har trege HDD disker, og det er mye aktivitet på server.
- PhysicalDisk: Disk Bytes/Sec: Gjenomsnittlig hvor mye bytes går til eller fra disk per sekund. Bør sammenliknes med baseline. En nedgang i verdien kan tyde på en disk som ikke fungerer optimalt, og som etterhvert kan feile.
- PhysicalDisk: Avg. Disk Bytes/Transfer: Gjenomsnittlig hvor mye bytes blir lest eller skrevet til disk per sekund. Bør sammenliknes med baseline. En nedgang i verdien kan tyde på en disk som ikke fungerer optimalt, og som etterhvert kan feile.
- PhysicalDisk: Current Queue Length: Antall ventende diskforespørsler, bør være så lavt som mulig, helst under 2 per skive. For høy verdi kan indikere at disken ikke fungerer optimalt, eller at den ikke klarer å holde tritt med ativitetsnivået. Vurder da å oppgrader lagringssystemet.
- PhysicalDisk: % Disk Time: Prosentandel av tiden disken er opptatt. Bør være så lavt som mulig, helst under 80%. For høy verdi kan indikere at disken ikke fungerer optimalt, at den ikke klarer å holde tritt med ativitetsnivået, eller at et minneproblem fører til overdreven bruk av paging files (virtuelt minne). Sjekk for memory leak, eller oppgrader lagringssystemet.
- LogicalDisk: % Free Space: Prosentvis ledig plass på disken. Bør være så høy som mulig, helst over 20%. Hvis verdien er for lav kan man utvide eller legge til disk.
De fleste problemer i tilknyttning disker kan løses ved:
- Installer raskere disker, som SSD
- Installer flere disker og fordel data på dem (reduserer I/O per disk)
- Erstatt stand-alone disker med RAID
- Legg til flere disker i eksisterende RAID
Network counters
Overvåking av nettverk er mer komplisert, da det er mange faktorer utenfor serveen som påvirker ytelsen. Mistenker man nettverksproblemer bør man også undersøke utenfor maskinen, men for internt kan man sjekke følgende:
- Network Interface: Bytes Totalt/Sec: Antall bytes sendt til og fra per sekund. Bør sammenliknes med baseline. Nedgang i verdien kan tyde på en nettverksadapter som ikke fungerer optimalt, eller andre nettverksproblemer.
- Network Interface: Output Queue Length: Antall pakker som venter på å bli sendt, bør være så lavt som mulig, helst under 2. For høy verdi kan tyde på en nettverksadapter som ikke fungerer optimalt, eller andre nettverksproblemer.
- Server; Bytes Total/Sec: Antall bytes sendt/mottatt totalt for alle nettverksadaptre på systemet. Bør ikke være mer en 50% av total kapasitet. Hvis verdien er før høy, vurder å migrer applikasjoner til andre servere, eller oppgrader til raskere nettverk.
Hvis man mistenker at nettverket er problemet, kan man oppgradere det. Det er to måter å oppgradere på:
- Increse the speed of the network: Bytt ut alt av nettverksutstyr som er tregt, med raskere utstyr. Det kan være nettverksadaptere, svitsjer, rutere mm. Det kan til og med bety at man må oppgradere kablene i nettverket.
- Install additional network adapters in the server and redistribute the network: Hvis problemet er selve nettverksadapteren kan man installere flere adaptere for å øke båndbredden serveren er kapabel til. Man bør så designe flere subnet og fordele maskinene på de.
6.2.4 Configure alerts
Få administratorer har tid til å sitte og følge med på grafer. Da kan man konfigurere alarmer kalt Performance Counter Alarm. Den kan konfigureres til å sende e-post når verdier overstiger angitt grense.
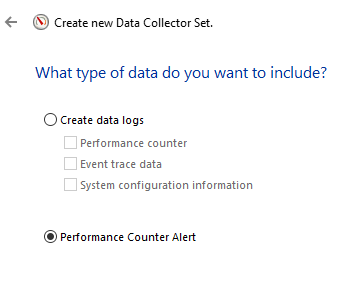
Man konfigurerer alarm når man oppretter et nytt data collector set, ved å velge Performance Counter Alert.
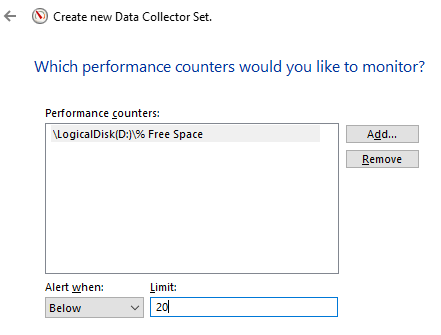
Man kan konfigurere en alarm til å gå av når det er mindre enn 20% ledig diskplass slik:
Trykk videre og Finnish. Ved å gå til Properties > Task på alarmen kan man sette handlinger den skal utføre. For å sende e-post kan man f.eks. spesifisere at den skal kjøre et skript som tar seg av det.
6.2.5 Monitor workloads using Resource Monitor
Ved å kjøre Resource Monitor får man opp et nyttig grensesnitt for å monitorere de fire kritiske komponentene på forskjellige performance counters.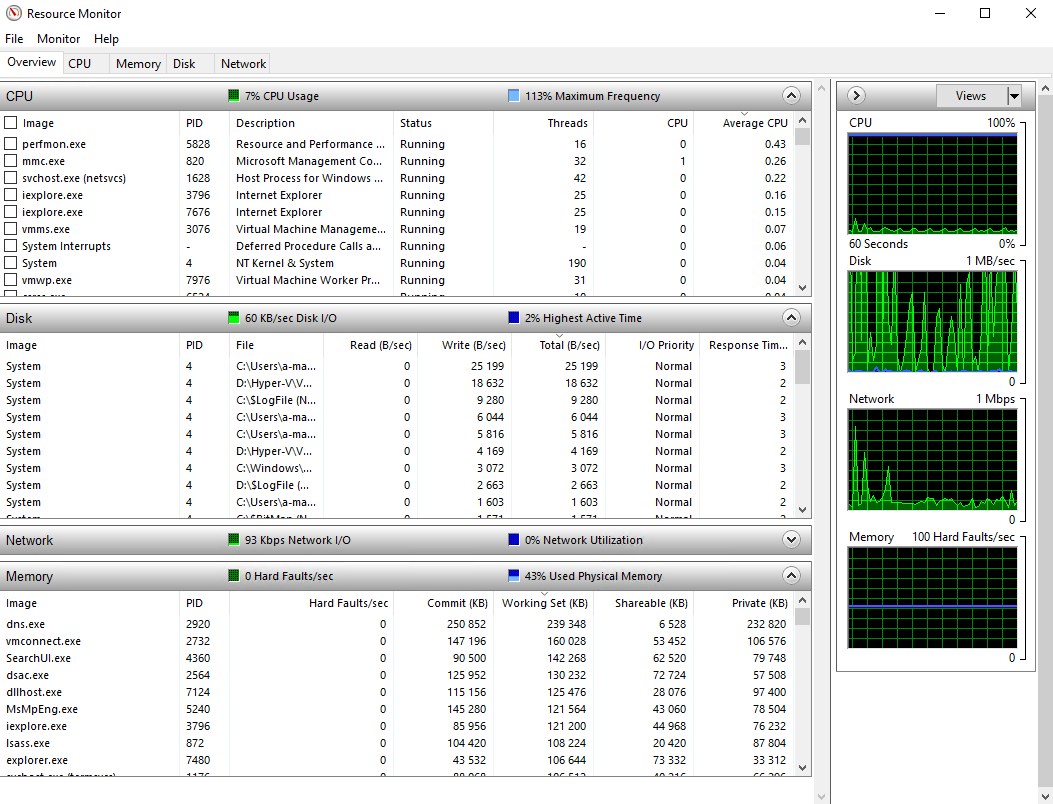
- CPU
- Image: Applikasjonen som bruker CPU ressurser
- PID: ID på prosessen til applikasjonen
- Status: Spesifiserer om applikasjonen kjører eller er suspendert
- Threads: Antall aktive tråder generert av applikasjonen
- CPU: Antall CPU sykluser så blir brukt av applikasjonen nå
- Average CPU: Prosentandel av total CPU kapasitet som blir brukt av pplikasjonen
- Disk
- Image: Applikasjonen som bruker diskressurser
- PID: ID på prosessen til applikasjonen
- File: Filen som blir lest eller skrevet til av applikasjonen
- Read: Hastighet på kjørende leseoperasjon av applikasjonen
- Write: Hastighet på kjørende skriveoperasjon av applikasjonen
- Total: Kombinert lese/skrive hastighet generert av applikasjonen
- I/O Priority: Prioriteten på I/O oppgaven som utføres
- Response Time: Intervall mellom en diskoppgave kommanderes og responsen som generees når den et utført
- Network
- Image: Applikasjonen som bruker nettverksressurser
- PID: ID på prosessen til applikasjonen
- Address: Navn eller IP adresse på systemet maskinen kommuniserer med
- Send: Hastigheten på nåværende sendeoperasjon
- Receive: Hastigheten på nåværende mottaksoperasjon
- Total: Kombinert hastighet av sende- og mottaksoperasjoner
- Memory
- Image: Applikasjonen som bruker minneressurser
- PID: ID på prosessen til applikasjonen
- Hard Faults/Sec: Antall hard faults per sekund generert av applikasjonen
- Commit: Mengde virtuelt minne som er reservert av applikasjonen
- Working Set: Mengde fysisk minne som blir brukt av applikasjonen
- Shareable: Mengde minne applikasjonen bruker, som den kan dele med andre applikasjoner
- Private: Mengde minne applikasjonen bruker, som den ikke kan dele med andre applikasjoner