5.4 Manage failover clustering
5.4.1 Configure role-specific settings, including continuously available shares
5.4.3 Configure failover and preference settings
5.4.4 Implement stretch and site-aware failover clusters
5.4.5 Enable and configure node fairness
5.4.1 Configure role-specific settings, including continuously available shares
Hver cluster rolle man installerer i Failover Cluster Manager eller med PowerShell, har sine egne innstillinger som er spesifikk for den rollen. Man kan se hva som er tilgjengelig for installert rolle under Actions i Failover Cluster Manager.
Virtual Machine Role Settings
For denne rollen får man mye av det samme man får i Hyper-V, man kan start og stoppe VMer, koble til de, eller endre innstillinger på VMene. Man kan også utføre live migrations, quick migrations og migrate VM storage.
Continuously available share settings
Når man installerer File Server cluster rollen, kan man velge mellom å opprette en vanlig filtjener, eller en Scale-Out File Server (SoFS). SoFS er designet for å tilby lagring til applikasjoner, som Hyper-V og SQL Server. Begge rollene lar deg opprette shares som er continuously available gjennom bruk av SMB 3.0 protokollen. SMB 3.0 inkluderer forbedringer som er spesielt nyttig i et cluster:
- SMB Transparent Failover: Lar klientsesjoner flyttes fra en node til en annen, uten avbrudd. Dette er aktivert som standard på Failover Cluster file server shares. Merk at både klient og server må støtte SMB 3.0.
- SMB Scale-Out: Lar sharet kunne aksesseres av klienter fra alle noder i clusteret samtidig.
- SMB Multichannel: Lar filtjener kombinere båndbredde fra flere nettverksadaptere, for å øke ytelse og feiltoleranse. SMB kan automatisk detektere at man har flere adaptere, og ta de i bruk.
- SMB Direct: Bruker Remote Direct Memory Access (RDMA) til å utføre direkte minneoverføringer mellom servere.
- SMB Encryption: Ende-til-ende kryptering med AES.
I New Share Wizard kan man huke av Enable Continuous Availability for å aktivere SMB Transparent Failover, og Encrypt Data Access for å aktivere SMB Encryption.
5.4.2 Configure VM monitoring
EN av fordelen med Hyper-V i et cluster er at clusteret kan overvåke spesifikke tjenester på VMene, rapportere når et problem oppstår, og ta handlinger som man kan konfigurere. Slik kan man ta en automatisk restart om en service feiler på en VM, eller flytte den til en annen node når et problem oppstår. For å ta i bruk VM Monitoring må VMen møte følgende krav:
- Den må være i samme domene som Hyper-V hosten
- Windows Firewall på VM må ha inbound rules i Virtual Machine Monitoring gruppen aktivert
- Hyper-V cluster administrator må være lokal admin på VMene
For å aktivere overvåking for en VM: Failover Cluster Manager > Roles > Velg VM > Actions > More Actions > Configure Monitoring > Velg tjenester som skal overvåkes.
Med PowerShell:
Add-ClusterVMMonitoredItem -VirtualMachine clustervm4 -Service Spooler
Når en tjeneste feiler, vil Service Control Manager forsøke å startede igjen som definert i servicen.

Hvis den ikke klarer det, vil clusteret ta over og prøve egne handlinger:
- Oppretter et innslag i hendelsesloggen (System) med ID 1250
- Clusteret endrer status på VM til Application in VM Critical
- Clusteret restarter VM på samme node
Man kan endre disse aktivitetene i Virtual Machine Cluster WMI Properties.
5.4.3 Configure failover and preference settings
En failover er når en rolle som kjører på en cluster node, ikke lengre kan kjøre, og flyttestil en annen cluster node. Det er mange grunner til at en failover kan skje; strømmen kan gå, software kan krasje, eller en administrator kan ha slått av noden for vedlikehold. En failback er når clusteret flytter rollen tilbake til opprinnelig node, etter problemet er løst.
Administratorer kan kontrollere oppførselen til clustered ved failover. Ved å velge en rolle og trykke på Properties kan man sette preferred owner som setter hvilke noder clusteret bør velge hvis de er tilgjengelig. Man kan også sette prioritet på rollen for å angi når den skal starte i forhold til de andre rollene: High, Medium og Low.
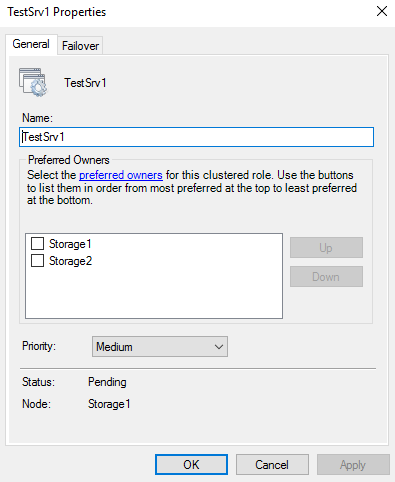
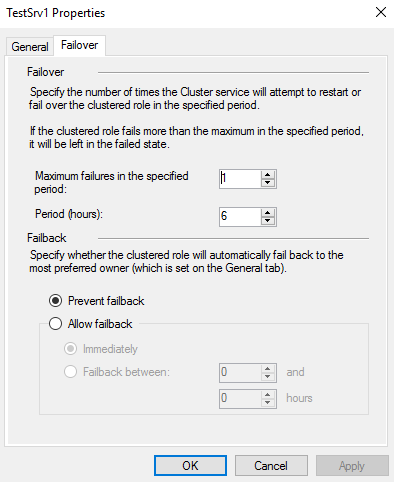
På Failover fanen kan man spesifiere maks antall ganger clusteret skal forsøke å restarte rollen, eller om den skal flyttes til en annen node i intervallet som er spesifisert. Man kan også velge om rollen skal faile tilbake til preferred node, og om den skal gjøre det med en gang den er oppe igjen, eller om man skal vente en stund.
5.4.4 Implement stretch and site-aware failover clusters
Noen ganger kan feil skje på en større skala enn et cluster kan håndtere. Det er kanskje ikke lengre snakk om disker og servere, men bygninger eller byer. Av den grunnen har man stretched clusters, som er cluster som har nodene sine fordelt på flere lokasjoner, gjerne i forskjellige byer. Slik at hvis en katastrofe inntreffer så man failover rollene til noder som er langt unna, og forhåpentligvis ikke har samme problemer.
Fordi det som regel ikke er praktisk å bruke ett shared storage for alle nodene i et stretch cluster, bruker mange stretch clustere asymmetrisk lagring, hvor hver lokasjon har sitt eget shared storage system. Man kan så bruke Storage Replica til å synkronisere data mellom lokasjonene.
For at et cluster skal vite hvilken lokasjon nodene er på, og hvor den skal faile over til, har man muligheten til å lage et site-aware failover cluster. Her får hver node et eget attributt som sier noe om lokasjonen (fault domain), og denne informasjonen brukes til å bestemme hvor man skal faile over.
For å lage et site-aware failover cluster bruker man først denne kommandoen for å opprette lokasjonene :
New-ClusterFaultDomain -Name Oslo -Type Site -Description "Primary" -Location "Oslo, Oslo"
New-ClusterFaultDomain -Name Trondheim -Type Site -Description "Primary" -Location "Trondheim, Sør-Trøndelag"
Så legger man til noder i lokasjonene:
Set-ClusterFaultDomain -Name node1 -Parent Oslo
Set-ClusterFaultDomain -Name node2 -Parent Trondheim
Når man har gjort dette vil clusteret bruker informasjonen i forbindelse med failover. Clusteret vil først forsøke å flytte en rolle til en node i samme lokasjon så lenge det er tilgjengelige noder der. Hvis det ikke er noen tilgjengelige noder der, vil clusteret forsøke å flytte rollen til en node i en annen lokasjon. Dette kalles failover affinity. Clustered Shared Volumes vil også forsøke å distribuere tilkobliner til noder i samme lokasjon først.
Det er mulig å konfigurere heartbeat innstillinger som clusteret bruker for å sjekke om en node er tilgjengelig. I et stretch cluster kan latency være en del høyere en på et LAN, da bør man justere innstillingene:
- CrossSiteDelay: Antall millisekund mellom hvert heartbeat som sendes. Standard er 1000ms.
- CrossSiteThreshold: Spesifiserer antall manglende heartbeats før clusteret kan regne med at en node i en anne lokasjon har feilet/er nede. Standard er 20.
Med PowerShell:
(Get-Cluster).CrossSiteDelay = 2000
(Get-Cluster).CrossSiteThreshold = 30
Man kan også sette en av lokasjonene til å være preferrert lokasjon for clusteret. Når man gjør dette, vil roller starte på foretrukket cluster ved en "cold start" av clusteret. I tillegg vil preferrert lokasjon seire i en quorum avstemming, og den andre lokasjonen vil gå ned.
(Get-Cluster).PreferredSite = Oslo
5.4.5 Enable and configure node fairness
Node fairness er en feature i Windows Server 2016, som forsøker å balansere distribusjon mellom noder i et Hyper-V cluster. Den virker ved å evaluere minne og CPU belastning på hver node over tid. Når clusteret oppdager en overbelastet node vil den lette lasten ved å live migrere VMer over til noder som er underbelastet (tar fortsatt hensyn til fault domain og preferred owners).
Denne featuren er aktivert som standard, men man kan konfigurere om den kjører og når lastbalansering inntreffer. Det gjør man i Properties på clusteret.
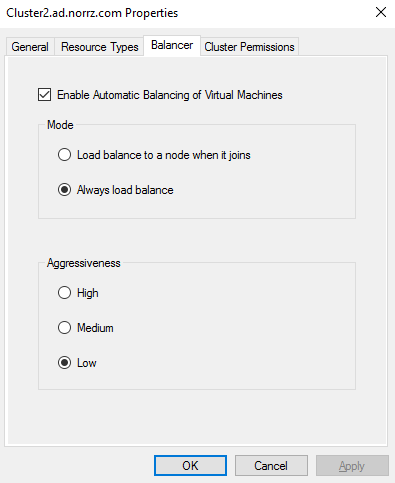
Med PowerShell:
# Spesifiserer om node fairness skal kjøre, og hvor ofte den skal lastbalansere
# 0: Node fairness er deaktivert
# 1: Lastbalansering kun når en node joiner clusteret
# 2: Lastbalansering når en node joiner clusteret, og vert 30 minutt videre
(Get-Cluster).AutoBalancerMode = [0|1|2]
# Spesifiserer hvor aggressivt node fairness skal være i vurdering av lasten på VMene
# 0: Low. Migrer VMer når hosten er mer en 80% belastet
# 1: Medium. Migrer VMer når hosten er mer en 70% belastet
# 2: High. Migrer VMer når hosten er mer en 60% belastet
(Get-Cluster).AutoBalancerLevel = [0|1|2]