5.2 Implement failover clustering
5.2.1 Implement Workgroup, Single, and Multi Domain clusters
5.2.3 Configure cluster networking
5.2.4 Restore single node or cluster configuration
5.2.5 Configure cluster storage
5.2.6 Implement Cluster-Aware Updating
5.2.7 Implement Cluster Operating System Rolling Upgrade
5.2.8 Configure and optimize cluster shared volumes (CSVs)
5.2.9 Configure clusters without network names
5.2.10 Implement Scale-Out File Server (SoFS)
5.2.11 Determine different scenarios for the use of SoFS vs. File Server for general use
5.2.12 Determine usage scenarios for implementing guest clustering
5.2.13 Implement a Clustered Storage Spaces solution using Shared SAS storage enclosures
5.2.14 Implement Storage Replica
5.2.15 Implement Cloud Witness
5.2.16 Implement VM resiliency
5.2.17 Implement shared VHDX as a storage solution for guest clusters
Et failover cluster er en gruppe på to eller flere servere, fysiske eller virtulle, som kjører samme applikasjon. De fungerer som en entitet og samarbeider om å levere applikasjonen. Cluster applikasjoner er typisk viktige applikasjoner, som database og email , eller infrastrukturtjenester, som Hyper-V og filtjenere. Hver server i et cluster kalles en node, og man kan enkelt legge til flere noder etter behov.
I Windows Server 2016, støtter verktøyene i Failover Clustering featuren opp til 64 noder, og 8000 virtuelle maskiner, med maksimum 1024 VMer per node. Selv om man bare skal sette opp et failover cluster med to noder, om det så er VMer på en Hyper-V server, er det fortsatt noen forutsetninger som må være på plass.
- Servere: Nodene i et cluster må være så identiske i hardware konfigurasjon som mulig
- Operativsystem: Alle noder må kjøre samme versjon og utgave av operativsystemet, inkl. samme patchenivå
- Lagring: Failover clustere bruker som regel delt lagring, shared storage, som et SAN eller NAS. Før var dette krevende, men takket være iSCSI er dette nå enkelt å få til.
- Nettverk: I større miljøer bør det være et eget nettverk dedikert til cluster trafikk, det samme gjelder for lagringsinfrastrukturen også.
- Applikasjoner: I tillegg til hardware, må man også vurdere kravene for applikasjonen
Failover Cluster Manager inkluderer en Wizard for å validere konfigurasjonen, og sjekke om man kan sette opp et cluster. Man kan også gjøre det med PowerShell:
Test-Cluster
Når valideringen er ok, kan man begynne å opprette clusteret. Med PowerShell:
New-Cluster -Name Cluster1 -Node Storage1, Storage2
Clusteret er en egen entitet, med eget navn og ip adresse. Har man DHCP vil cluster automatisk få ip. Hvis ikke man har DHCP må man sette det manuelt.
New-Cluster -Name Cluster1 -Node Storage1, Storage2 -StaticAddress 10.0.0.100
Clusteret har et eget objekt i Active Directory, kalt Cluster Name Object (CNO). Når clusteret e roperasjonelt vil klienter adressere clusteret og ikke nodene for å nå tjenesten/applikasjonen.
5.2.1 Implement Workgroup, Single, and Multi Domain clusters
Før Windows Server 2016 måtte alle nodenevære meldt inn i samme ADDS domene, et single domain cluster. I WIndows Server 2016 er det imidlertid mulig å bruke noder som er medlem av forskjellige domener, et multi domain cluster, eller ikke medlem av noe domene, et workgroup cluster. Failover cluster bruker mange tjenester mot AD, og har man ikke domene må clusteret få tilgang til DNS for å opprette cluster network name. Noen applikasjoner er avhengig av AD for autentisering, mens andre, som SQL Server, har sin egen autentiseringsmekanisme. SQL Server passer derfor i multi domain cluster og workgroup cluster, i tillegg til single domain cluster.
Før man kan opprette et multi-domain eller workgroup cluster må man gjøre følgende oppgaver:
Opprett en lokal konto
Uten Active Directory, må man opprette en lokal administratorbruker på hver node, med samme brukernavn og passord. Man kan godt bruke built-in Administrator til dette formålet. Dersom man ikke bruker innebygd administrator må man i tillegg kjøre denne kommandoen på hver node:
New-ItemProperty -Path HKLM:\SOFTWARE\Microsoft\Windows\CurrentVersion\Policies\System -Name LocalAccountTokenFilterPolicy -Value 1
Legg til DNS suffixer
Uten Active Directory, må clusteret bruke DNS for å lokalisere cluster noder, og clusteret selv. Det er ingen direkte måte å gjøre det på med PowerShell, men man kan bruke Group Policy: Computer Configuration\Policies\Administrative Templates\Network\DNS Client og aktiver Primary DNS Suffix. Legg inn et DNS suffix.
For et multi-domain cluster må man i tillegg endre på det manuelt på hver node under Nettverksadapter > Internet Protocol Version 4 (TCP/IP) > Advanced > DNS > Append these DNS suffixes.
Med PowerShell:
Set-DnsClientGlobalSetting -SuffixSearchList @("ad.norrz.com", "serverkurs.no")
Lag en workgroup eller multi-domain cluster
Man kan så fortsette med opprettelse av clusteret:
# Samme som for single domain cluster, men med et ekstra parameter
New-Cluster -Name Cluster1 -Node Storage1, Storage2 -AdministrativeAccesspoint DNS
5.2.2 Configure quorum
Quorum er en funksjon i et Failover Cluster som forhindrer at et cluster blir splittet i to, hvor hver del fortsetter å kjøre, en split-brain situasjon. F.eks. en nettverksfeil fører til at et 6 noder cluster blir splittet inn i to 3 noder cluster. Uten quorum kunne de to clusterene fort kommet ut av synk, og dataen blitt veldig forskjellig.
Quorum gir hver node en stemme, og i mange tilfeller har man en witness disk, som også får en stemme, for å forhindre uavgjort ved avstemming. Alle noder monitorerer kontinuerlig alle stemmene fra de nodene og vitnet. Hvis en node detekterer at antallet stemmer er under 50% + 1, vil den fjerne seg selv fra clusteret. Hvis man har en witness disk vil den halvdelen av clusteret som når vitnedisken fortsette å fungere, mens den andre halvdelen vil melde seg ut av clusteret.
Quorum witnesses
Når man lager et nytt cluster blir det opprettet en quorum konfigurasjon som, i de fleste tilfeller, er passende for clusteret. Den baserer seg på antall noder og tilgjengelig lagring. Standard er at hver node får en stemme (vote), og hvis det er et partall med antall noder, så opprettes det en witness disk, som får en stemme. Den eneste funksjonen til vitnet er å avgjøre ved uavgjort antall stemmer. Det finnes tre ulike typer ressurser som kan være vitne:
- Disk Witness: En dedikert disk i clusterets delte lagringsløsning. Typisk for cluster som er lokalisert en enkel plass.
- File Share Witness: Et SMB share med en Witness.log fil som inneholder informasjon om clusteret. Typisk for clustere som er splittet på forskjellige lokasjoner, med replikert lagring.
- Cloud Witness: En blob er lagret i Microsoft Azure, skyen. Dette er et nytt alternativ i WIndows Server 2016, designet for å dekke clustere som er splittet på flere datasentre på forskjellige lokasjoner.
Dynamic quorum management
Dynamic quorum management er en funksjon i Windows Server 2016 som gjør at et cluster kan fortsette å kjøre i situasjoner hvor det hadde stoppet i tidligere utgaver av Failover Cluster. Når en node forlater clusteret, vil dynamic quorum management automatisk fjerne stemmen til noden, slik at avstemmingen baserer seg på de gjenværende stemmene. Hvis et cluster på 5 noder, mister 3 noder, vil de gjenværende 2 nodene fjerne seg fra clusteret om man ikke har dynamic quorum management. Da ender man opp uten noe cluster. Med dynamic quorum management vil clusteret fortsette å kjøre, for da er antallet stemmer redusert fra 5 til 2. Så lenge det er minst en node igjen, vil clusteret fortsette å fungere.
Modifisere Quorum konfigurasjon
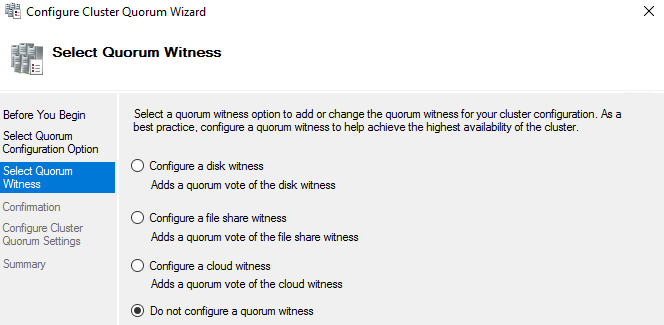
Man kan konfigurere quorum, enten med Set-ClusterQuorum eller Configure Cluster Quorum Wizard.
Man kan velge mellom:
- Use default quorum configuration: Lar wizarden automatisk velge konfigurasjon for quorum
- Select the quorum witness: Lar deg legge til vitne, og spesifisere type vitne. Man kan også fjerne vitner.
- Advanced quorum configuration: Lar deg spesifisere hvilke noder som skal ha stemmer i quorum, i tillegg til får man samme muligheter som i Select the quorum witness.

Med PowerShell:
# Konfigurer quorum med at majoriteten av nodene vinner fram, bruker ikke noe vitne
Set-ClusterQuorum -Cluster Cluster1 -NodeMajority
# Konfigurere quorum med stemme til hver node + et vitne
Set-ClusterQuorum -Cluster Cluster1 -NodeAndDiskMajority "Cluster disk 1"
# Konfigurer en node til å ikke ha en stemme
(Get-ClusterNode ClusterNode1).NodeWeight = 0
NB. Mange av PowerShell kommandoene for Failover Cluster fungerer ikke fra en annen maskin. Kjør de lokalt når det er mulig.
Konfigurere et vitne
Vitne blir opprettet automatisk når clusteret har et partall antall noder. Man kan ikek ha flere vitner i et cluster, og det er anbefalt å ikke opprette vitne om det resulterer i et partall antall stemmer. Når nodene har delt lagring er disk vitne anbefalt.
Configure Cluster Quorum Wizard > Select the quorum witness
Modifisere quorum avstemming
I de fleste tilfeller skal alle nodene ha en stemme. Det er dog mulig å konfigurere et cluster hvor bare witness disk har en stemme. Da vil den den delen av clusteret som har vitnet, fortsette å kjøre, men da blir vitnet et single point of failure. Ryker vitnet, så ryker hele clusteret.
Det er situasjoner hvor det kan være ønskelig å fjerne en stemme for en spesifikk node. F.eks. hvis man har en node på en annen lokasjon, kun som bakup med manuell fail over hvis en katastrofe skulle inntre.
NB. Om en node ahr en stemme eller ikke, påvirker ikke dens funksjonalitet i clusteret. Den er fortsatt like aktiv som de andre.
5.2.3 Configure cluster networking
Nettverkskommunikasjon er kritisk for high availability for Failover clusteret. Å separere trafikk til forskjellige nettverk, og redundate ruter, hjelper å sikre tilgjengeligheten til clusteret. Avhengig av ype cluster kan man ønsker å separere trafikk i følgende kategorier.
- Client Communication: Tilgang for klienter til applikasjonen på clusteret har høyest prioritet
- Cluster Communication: Heartbeat og annen kommunikasjon mellom nodene er essensiel for clusterets funksjoner
- iSCSI: Lagringsnett
- Live Migration: På et Hyper-V cluster er Live Migration kritisk for å sikre kontinuitet for VMene
Velge hardware til nettverk
Man bør gå for mest mulig redundans i nettverket for å unngå single point of failure. Noen anbefalinger er:
- Bruk separate nettverksadaptere, i stedet for adaptere med flere interface på samme adapter
- Bruk adaptere av forskjellig type/modell for å unngå at en driverfeil tar ut alle adapterene
- Bruk separate, fysiske svitsjer i stedet for VLAN på en stor svitsj
- Lag redundante tilkoblinger alle plasser det er mulig, spesielt for klientkommunikasjon
- For nettverk med redundante tilkoblinger, bruk NIC Teaming for å tilby failover kapabilitet
Modifisere standardvalg i nettverket
Når man oppretter et cluster gjør systemet en del standard valg.
- Et nettverk med iSCSI trafikk er deaktivert for cluster kommunikasjon
- Nettverk uten default gateway er kun konfigurert for cluster kommunikasjon
- Nettverk med default gateway adresse er konfigurert både for cluster og klient kommunikasjon
Man kan sjekke status på nettverkene på Failover Cluster Manager > Networks eller med PowerShell:
Get-ClusterNetwork
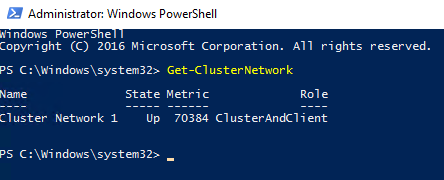
Man kan modifisere nettverksinnstillingene i Failover Cluster Manager eller i PowerShell med Get-ClusterNetwork.
Velg et nettverk og trykk på Properties. Velg fra følgende alternativer:
- Allow Cluster communication on this network
- Allow clients to connect through this network
- Do not allow cluster communication on this network
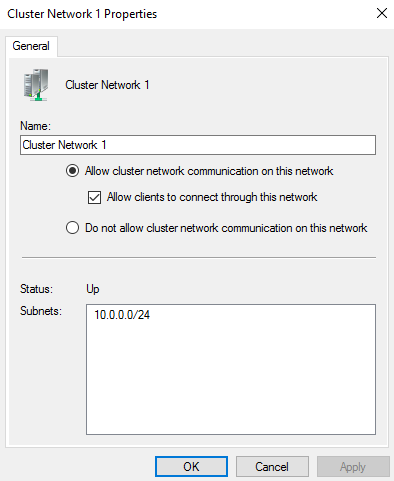
Med PowerShell:
(Get-ClusterNetwork -Name "Cluster Network 1").Role = 3
Mulige verdier er som følger:
- 0: Deaktiver for cluster kommunikasjon
- 1: Aktivert for bare cluster kommunikasjon
- 3: Aktivert for både cluster og klient kommunikasjon
NB. I mange tilfeller er PowerShell kommandoene for Failover Cluster lite intuitive..
5.2.4 Restore single node or cluster configuration
Failover clustere gir feiltoleranse, men de fjerner ikke behovet for backup. Uansett hvilken form for shared storage du bruker bør det være en backup strategi på plass. Et problem med backup av cluster er at Windows Server Backup er begrenset når det kommer til backup av Cluster Shared Volume (CSV), men den kan ta backup av cluster databasen. Databasen lagres på hver node i clusteret, i tillegg på vitnet om det finnes. Cluster service på hver node er ansvarlig for å replikere databasen på tvers av noden.
Hvis en node detter ut og må gjenopprettes kan man bare ta en full restore, da databasen vil bli oppdatert automatisk når noden er oppe igjen. Det kalles en non-authorative backup. En annen mulighet er det som kalles authoriative backup, hvor man ikke vil at databsen skal oppdatere seg. For å gjøre dette med Windows Server Backup, må man kjøre Wbadmin.exe.
For å se tilgjengelige versjoner man kan restore:
wbadmin get versions
For å se innhold i en versjon:
wbadmin get items -version:08/03/2018:19:50
For å bare gjenopprette databasen:
wbadmin start recovery -itemtype:app -items:cluster -version:08/03/2018:19:50
5.2.5 Configure cluster storage
For at et failover cluster skal hoste en highly available applikasjon, må alle nodene ha tilgang til applikasjonsdataen. Derfor må de ha en delt lagringsløsning. I WIndows Server 2016 er delt lagring et krav for Failover Clustering featuren.
- Fibre Channel: SAN protkoll, høy hastighet, krever spesialisert utstyr og ekspertise. Finnes nå som en versjon som kjører på Ethernet (FCoE), i stedet for fiberoptikk, som er rimeligere.
- Serial Attached SCSI (SAS): SCSI er en Bus-basert lagringsprotkoll, standard for høyhastighets lokal lagring. SAS varianten bruker seriell kommunikasjon til å øke maks lengde på bussen, samtidig som den bruker mindre kabler og koblinger en originalen.
- Internet SCSI (iSCSI): En variant av SCSI protokollen som sender SCSI trafikk over nettverket. Se kap. 2.2.5 for mer info.
Av disse alternativene er Fibre Channel dyrest, og iSCSI billigst.
NB. Ved å bruke Hyper-V og iSCSI, er det mulig å implementere et failover cluster på en enkelt fysisk maskin, for lab eller testformål. Ytelsesnivået på clusteret vil ikke bli noe særlig, og ikke noe man kan bruke i produksjonsmiljøer.
For å legge til disker går man til Failover Cluster Manager > Storage > Disks > Add Disk
Man kan opprette en clustered pool av diskene. Prosessen er den samme som for Storage Spaces, men den blir tilgjengelig for alle nodene. Et clustered storage pool krever minst tre disker, med minst 4 GB kapasitet hver.
Failover Cluster Manager > Storage > Pools > New Storage Pool
5.2.6 Implement Cluster-Aware Updating
Et av forutsetningene for å installere Failover CLustering er at alle nodene har samme OS og patchenivå. Cluster-Aware Updating (CAU) er et verktøy som følger med Failover Clustering, og kan oppdatere nodene systematisk, med minimalt med nedetid. Den bruker live migration for å flytte rollene vekk fra noden, så oppdateres noden, og rollene kan migreres tilbake.
CAU krever en egen maskin til å fungere som Update Coordinator, som styrer oppdateringsløpet for clusteret.
- Self-Updating Mode: En av nodene har CAU rollen installert, og lar den være Update Coordinator. Administratorer kan konfigurere en schedule for når clusteret skal oppdateres. Når alle de andre nodene er oppdatert, flyttes CAU rollen til en annen node, og den som var Update Coordinator blir nå oppdatert. Dette er en helautomatisk prosess.
- Remote Updating Mode: En maskin utenfor clusteret er konfigurert som Update Coordinator, og administratorer kan mnauelt sette i gang oppdateringer. Det kan ikke automatiseres, og Update Coordinator blir ikke oppdatert selv.
For å ta i bruk CAU i Self-Updating Mode, må hver node i clusteret ha Failover Clustering feature med management tools installert. I et Remote Updating Mode, trenger Update Coordinator kun å ha Failover Clustering Management Tools installert.
# Self-Updating Mode
Install-WindowsFeature -Name Failover-Clustering -IncludeManagementTools
# Remote Updating Mode
Install-WindowsFeature -Name RSAT-Clustering
Det er krav for CAU, men de fleste er allerede dekket i WIndows Server 2016. Man kan sjekke det ved å trykke på Analyze Cluster Updating Readiness i Cluster-Aware Updating konsollet. Eller med PowerShell:
Eller med PowerShell:
Test-CauSetup
For å konfigurere CAU i self-updating mode: Cluster-Aware Updating > Configure cluster self-updating. Dette kjører en Wizard, som legger til clustered role, og lager en schedule for self-updates. Man kan også spesifisere andre ting; som maks antall ganger man kan prøve på nytt per node, og i hvilken rekkefølge nodene skal oppdateres. Med PowerShell:
Add-CAUClusterRole -ClusterName Cluster1 -DaysOfWeek Saturday -WeeksInterval 4 -MaxRetriesPerNode 2 -NodeOrder node1, node2, node3
Man kan så vente til den kjører av seg selv på schedule, eller man kan sette i gang en oppdateringssyklus manuelt, ved å trykke på Apply Updates to this cluster.
5.2.7 Implement Cluster Operating System Rolling Upgrade
Windows Server 2016 støtter en teknikk kalt Cluster Operating System Rolling Upgrade, som gjør det mulig å Hyper-V eller Scale-Out File Server cluster fra Windows Server 2012 R2 til Windows Server 2016, uten å ta ned hele clusteret. Det er ikke et verktøy eller en wizard, men en teknikk man kan bruke for å få til dette, og det er ikke automatisert. Det som muliggjør denne teknikken er en ny Cluster Operational Mode kalt mixed-OS. I motsetning til i tidligere versjoner av Widnows, kan et cluster i Windows Server 2016 fungere midlertidig med noder på forskjellig OS. Teknikken er som følger:
- Pause noden
- Drain noden for cluster roller
- Kast (evict) noden ut av clusteret
- Reformater systemdisken, og utfør en clean installasjon av Windows Server 2016
- Konfigurer nettverk og lagring
- Installer Failover Clustering feature
- Legg til noden i clusteret
- Sett opp cluster roller på nytt
Når Windows Server 2016 legges til i cluster med WIndows Server 2012 R2, går den inn i kompabilitetsmodus. Det gjør at den kan fungere sammen med Windows Server 2012 R2. Den forblir i kompabilitetsmodus til alle nodene i clusteret er oppgradert, til da er alle nye Windows Server 2016 Failover Clustering features utilgjengelige.
Når alle nodene er oppgradert, må man manuelt øke cluster functional level:
Update-ClusterFunctionalLevel
NB! Når man øker Cluster functional level, kan man ikke gå tilbake til tidligere versjoner lengre. Det er "point of no return".
NB. Microsoft anbefaler å bli ferdig med hele clusteret innen 1 måned, mixed-OS mode er ikke ment som en permanent løsning.
5.2.8 Configure and optimize cluster shared volumes (CSVs)
Når man oppretter et cluster bruker man de fysiske diskene til å lage en storage pool, som man igjen lager virtuelle disker fra. For de virtuelle diskene kan man se i Failover Cluster Manager, hvem som er designated owner av disken. Den som er owner vil ha diskene montert i filsystemet sitt, den andre noden vil se disken som reservert, og kan ikke bruke den.

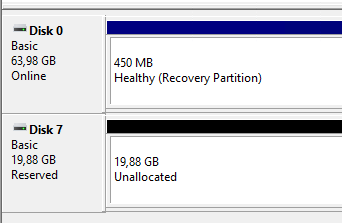
Dette er fordi NTFS ikke er designet for å bli aksessert av mer enn et OS om gangen. Løsningen er Cluster Shared Volume (CSV), som oppretter et pseudo-filsystem kalt CSVFS som legger seg oppå NTFS. Problemet med at flere noder prøver å aksessere samme NTFS disk, er at de prøver å aksessere og modifisere samme metadata, som kontrollerer strukturen på disken. Det kan føre til korrupsjon av metadaten, og disken.
CSVFS er et filter som lar flere noder utføre I/O operasjoner på disken, men forhindrer andre en designated owner, også kalt coordinator, til å manipulere metadata på disken.
Legge til disker på CSV
For å legge til virtuelle disker i CSV bruker man PowerShell:
Add-ClusterSharedVolume -Name vDisk2
Når man har gjort det kan man se at disken er montert i mappen C:\ClusterStorage på alle nodene.
For å endre eier, cooridnator, til disken kan man i Failover Cluster Manager høyreklikke på disken og velge Move.
Optimere CSV
CSV kommer med en cache som skal forbedre ytelsen på intensive leseoperasjoner. Den kan være nyttig på Hyper-V og SoFS clustere. Standard i Windows Server 2016 er at størrelsen på cachen er 0. For å aktivere den kan man sette en størrelse manuelt (maks 80% av systemminnet):
# Spesifiser en størrelse i antall megabyte (MB)
(Get-Custer).BlockCacheSize = 512
Nyttige kommandoer
Når man fjerner en disk så blir ikke plassen den tok, frigjort i poolen. Her er noen nyttige kommandoer for å rydde opp (veldig kjekt å vite for lab-formål):
# Fjerner CSV volum
Get-ClusterSharedVolume -Name *vDisk2* | Remove-ClusterSharedVolume
# Fjerner virtuell disk
Get-VirtualDisk -FriendlyName vDisk2 | Remove-VirtualDisk -Confirm:$false
# Optimaliser poolen, rebalanserer bruken av de fysiske diskene
Get-StoragePool -FriendlyName S2D* | Optimize-StoragePool
NB. Når man fjerner en virtuell disk i GUI, så blir den ikke fjernet helt, defor får man ikke tilbake diskplass i poolen
5.2.9 Configure clusters without network names
Når man oppretter et Failover Cluster, blir det opprettet et maskinobjekt i AD, kalt cluster name object (CNO). CNO er clusterets administrative aksesspunkt. Noen clusterede applikasjoner oppretter også AD objekter, virtual computer objects (VCO), som representerer klient askesspunkt.
Det er mulig å opprette cluster som ikke bruker AD objekter, selv om det er med i et domene. Dette kalles et Active Directory-detached cluster. For dette er det nødvendig at den som oppretter clusteret også kan opprette objekter i AD eller bruke prestaged objects. I stedet for objekter i AD bruker et AD-Detached cluster DNS for navn til cluster, og client access points. Nodene må fortsatt være i domenet, og det brukes fortsatt Kerberos til autentisering mellom nodene, og NTLM for autentisering mot cluster navnet.
Dette kan skape problemer for applikasjoner som bruker kerberos til autentisering. Det betyr at følgende ikke er kompatibelt med AD-Detached cluster:
- Hyper-V
- BitLocker drive encryption
- Cluster-Aware Updating (når Self-Updating mode brukes)
Microsoft SQL Server kan bruke en egen autentiseringsmekanisme, og er derfor kompatibel.
For å lage et et AD-detached cluster:
New-Cluster -Name Cluster2 -Node sql1, sql2 -StaticAddress 10.0.0.100 -NoStorage -AdministrativeAccessPoint DNS
5.2.10 Implement Scale-Out File Server (SoFS)
Scale-Out File Server rollen oppretter filshare som er tilgjengelig på alle nodene i clusteret, samtidig. Hvis en node går ned vil CSV redirigere I/O til en annen node. SoFS øker effektiviteten til clusteret ved å kombinere båndbredden til alle nodene for filsystem I/O.
Cluster tildeler nettverk en Metric som baserer seg på hastighet og andre karakteristikker. Trafikk for redirigering av I/O går over det nettet som har lavest metric. Man kan administrere metric med PowerShell:
# Se hvilken metric de forskjellige nettene har
Get-ClusterNetwork
# Endre metric
(Get-ClusterNetwork -Name "Cluster network 1").Metric = 40000
For å ta i bruk SoFS må man har et cluster med CSV satt opp for alle nodene. Man går så til Failover Cluster Manager > Roles > Configure Role... > File Server > Scale-Out File Server for application data.
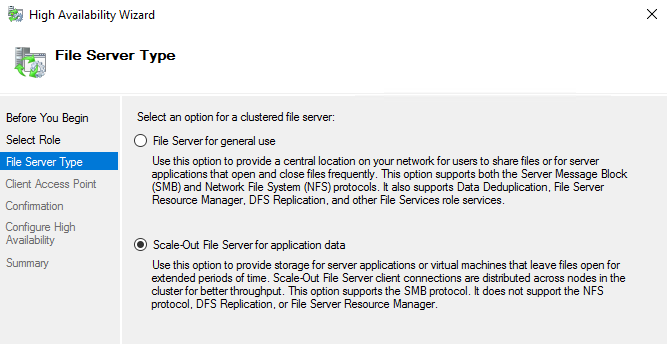
Velg et navn som klientene bruker for å nå SoFS-filtjeneren.
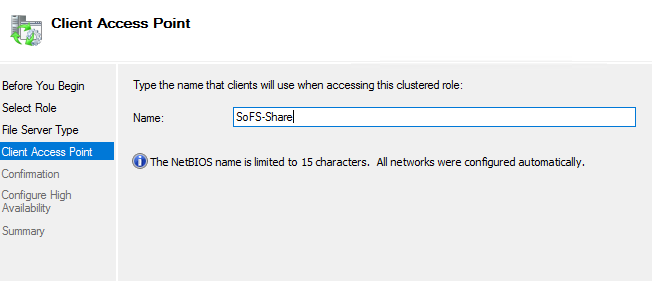
Med PowerShell:
Add-ClusterScaleOutFileServerRole -Name SoFS-Share
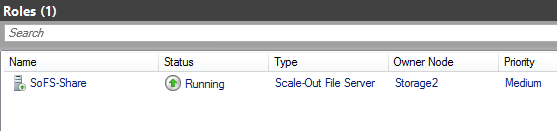
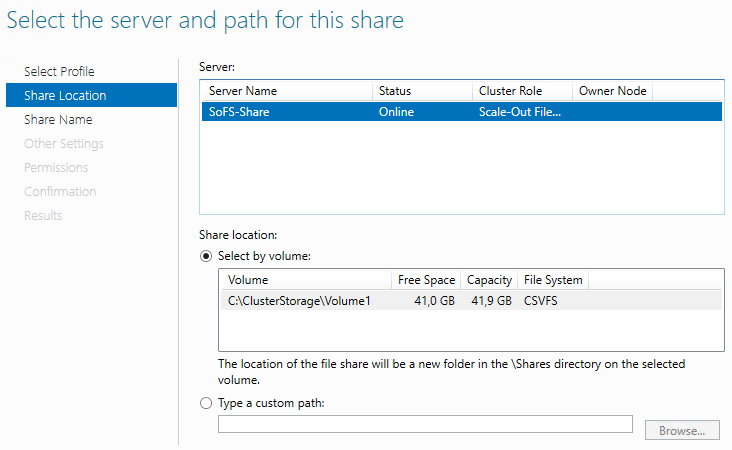
Man kan så gå videre med å opprette et share: Høyreklikk på rollen > Add File Share
Prosessen for å opprette et SoFS share er identisk med når man oppretter vanlige share.
Man kan så bruke sharet fra klienter, og man kan se at data lagres i CSVunder C:\ClusterStorage på alle nodene.
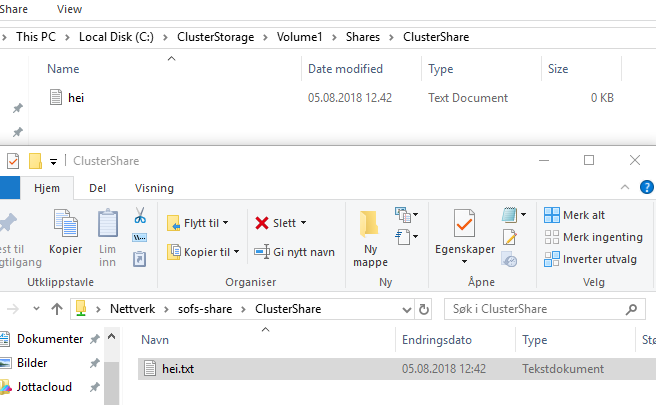
Med PowerShell:
New-SmbShare -Name ClusterShare2 -Path C:\ClusterStorage\Volume1 -FullAccess ad\storage1, ad\storage2 -ContinuouslyAvailable $true
Set-SmbPathAcl -ShareName ClusterShare2
5.2.11 Determine different scenarios for the use of SoFS vs. File Server for general use
Når man skal velge mellom rollene File Server for General Use og Scale-Out File Server for application data må man tenke på følgende ved SoFS:
- All I/O på metadata må gå via noden som er koordinator, noe som kan være en flaskehals når alle nodene tar imot I/O fra klientene. Derfor passer SoFS best med leseintensive applikasjoner, som ikke gjør så mye endringer, og holder store filer åpne i lengre tid. F.eks. Hyper-V og SQL Server.
- For å sikre continously availability på alle nodene, skrives data rett til disken og caches ikke i minne på noden. Det kan føre til dårligere ytelse enn hos en vanlig filtjener. Det fører dog til at mindre data går tapt om en node krasjer eller man får feil på cache.
Det betyr at jo større frekvens på metadata-endringer, jo mindre passer det med SoFS.